Reinforcement Learning for Soft Robots
ProjectThis is my MSR Final Research Project! It was conducted in the Spring and Fall quarters of 2022, within Northwestern's Robotic Matter Lab. I had the incredible fortune to be advised by Professors Ryan Truby and Matthew Elwin, and to collaborate with Professor Todd Murphey's lab.

Cover photo from a themed collection on soft robotics, Soft Matter
Background: Gait Optimization for Soft Systems
In this project, I am working with a soft-legged quadruped, with legs composed of Handed Shearing Auxetics (HSAs). These are flexible 3D printed structures with a negative Poisson's ratio, expanding and contracting when subjected to rotation. We print HSAs out of polyurethane-like material, using stereolithography.
An HSA is composed of two of these auxetic cylinders. When paired together, two HSA pairs can create a structure that can expand, contract, bend, and twist.

Kaarthik et al., “Motorized, untethered soft robots via 3D printed auxetics”, Soft Matter, 2022.
I joined the Robotic Matter Lab when Pranav Kaarthik was working with HSAs to create an quadruped. Using a hand-defined gait, he demonstrated untethered locomotion for over an hour, while carrying a payload of 1.5kg. This work appeared in "Motorized, untethered soft robots via 3D printed auxetics", accepted to Soft Matter in the Fall, and was the cover art for a themed collection on soft robotics!
My research builds upon this foundation, establishing reinforcement learning methods applicable to such a system - with the goal of learning an optimized gait that improves the robot's walking speed.
Challenges in Controlling Soft Systems
Soft robotics exhibit potential for safe human-robot interaction, operation in hazardous places, and more. However, their compliance, the very property that provides such benefit, is also a major challenge in controlling them. In the particular example of an HSA robot, the forward kinematics are unknown - the relationship between motor commands and leg displacement is unintuitive, and is further complicated by the compliant nature of the structures.
Additionally, as soft robots rely on material deformation to move, the lifespan of soft actuators is by definition limited by its material properties. This leads to actuation properties that vary over time.
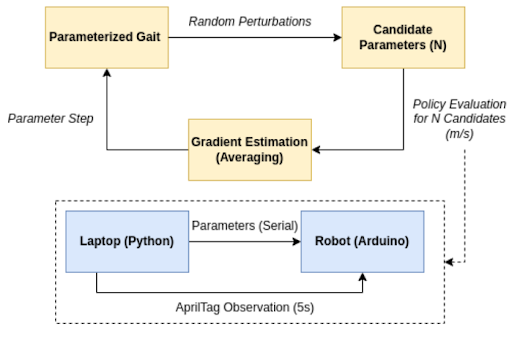
Initial Approach: Online Policy Gradient Estimation
These challenges led to a first attempt at reinforcement learning for such a system - online policy gradient estimation, with methods derived from Policy Gradient Reinforcement Learning for Fast Quadrupedal Locomotion, one of the earliest examples of learned legged locomotion from 2004. The intention for this method is to use the simplest learning architecture possible, and avoid the complexities of modeling & simulating such a complex dynamical system.
Nate Kohl and Peter Stone, “Policy Gradient Reinforcement Learning for Fast Quadrupedal Locomotion”, ICRA, 2004.
Here, I parameterized the values in the hand-tuned policy, while preserving the gait's structure. However, it was found that given the parameter space we were searching, the system was very brittle with respect to parameter perturbations. While it is certainly possible to have learned a more optimal gait using this method (and should I have had more time, I would've loved to explore further!), the timescales required (and therefore the number of motors and HSAs printed) was prohibitive. Thus, I led the initiative to pivot to a sim-to-real approach to learn gaits on this system.
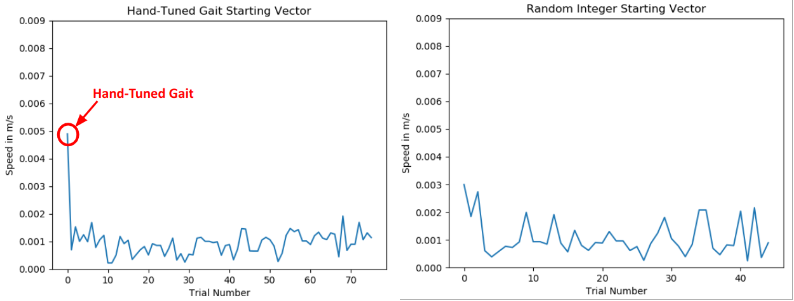
Results on a per-trial basis, using online policy gradient RL
Creating a Simulation Environment
I created a simulation environment based off of Pybullet, and made it compatible with OpenAI's Gym workflow, a useful framework for reinforcement learning tasks. The robot modeled in simulation, is defined by a URDF with two joints: a revolute and prismatic joint connected together.

HSA Robot, in Pybullet, moving its joints around
Policies Modulating Trajectory Generators
To learn a gait in simulation, I use the architecture Policies Modulating Trajectory Generators. This allows the agent to learn a policy for a gait like more 'conventional' reinforcement learning, but allows some prior knowledge to be added to bootstrap the simulation. It takes the form of a periodic Trajectory Generator, which in the original paper, defines the path in space that a robot's foot follows. It's defined by various parameters, which are learned by the policy given an observation.
The policy learns additional values, too, residual values that allow the policy to modulate the Trajectory Generator's output based on an observation (Euler angles, in this case). In the original and my implementation, it takes the form of X and Y offsets for each leg. It also learns a time offset value - which modulates the phase of each leg, transitioning the Trajectory Generator into a general-purpose point selection set for each timestep within the simulation.
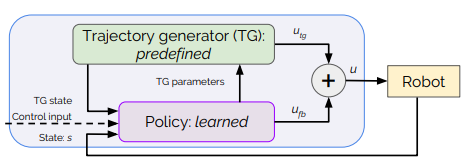
Iscen et al., “Policies Modulating Trajectory Generators”, Conference on Robot Learning (CoRL), 2018.
In order to improve the sim-to-real transfer effectiveness, I apply Gaussian noise to each set of simulation inputs, along with applying domain randomization for each rollout, increasing the robustness of the policy. Many implementation details are inspired by Linear Policies are Sufficient to Enable Low-Cost Quadrupedal Robots to Traverse Rough Terrain, where the application of residuals, gait time dilation, and domain randomization is critical to enable a rigid quadruped to walk and "stumble" through rough terrain without falling over.
Following this paper, I also implement a simple linear policy rather than a more complex neural network-based architecture, and use Augmented Random Search to train it. It trains in minutes on CPU, and converges on the order of only hundreds of rollouts.
Test Fixturing to Capture Dynamics
In order to enable sim-to-real transfer, I need to tackle the challenge of forward kinematics for the HSA quadruped. I chose to accomplish this in a computationally-efficient way possible, a simple lookup table to approximate the complex mapping between motor inputs and HSA displacement.
Furthermore, to match the simulation, I constrain leg movement to planar extensions, contractions, and bending. Due to the handed nature of the legs, it means that a given HSA position can be represented by two motor commands,
rather than four. Our servos that actuate the HSAs move approximately 180 degrees, so when considering 90 degrees as a nominal value, the parameter vector of motor inputs for each leg ends up being [M, 180-M, N, 180-N].
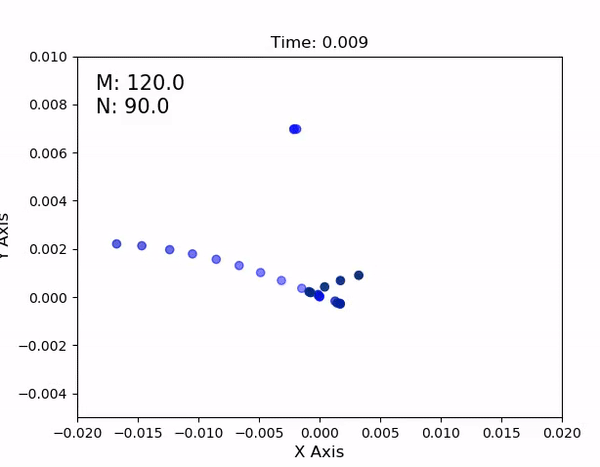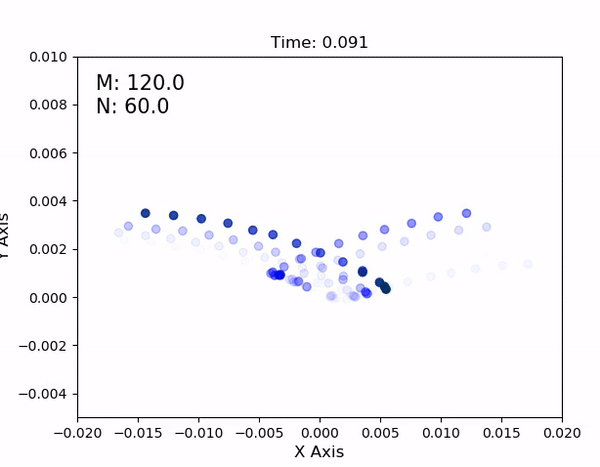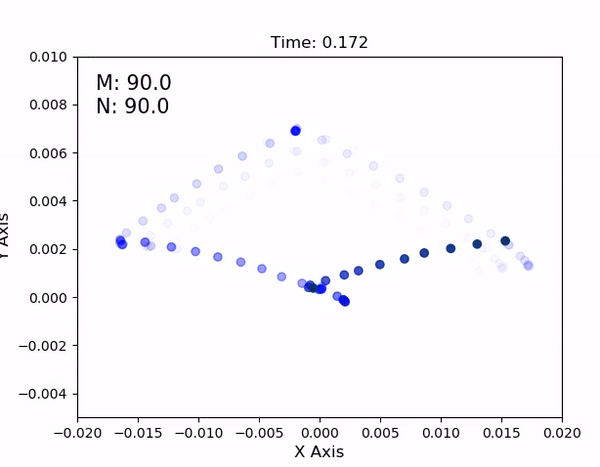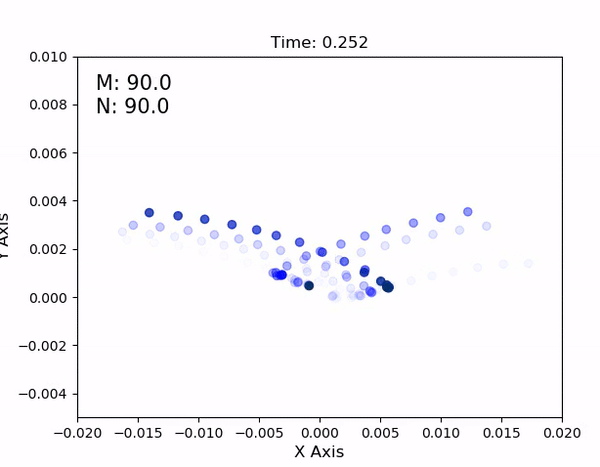
To simulate compliant behavior of the robot's legs under loading conditions similar to walking, I designed a test fixture for a single leg. Preloaded springs on each corner provide a constant force similar to one-quarter of the robot's expected weight, and allow the leg to contract without any resistive force. Extending the leg applies more force to "push the robot up".

Test fixture for capturing HSA dynamics
Using an AprilTag, I then perform a set of planar sweeps to cover the parameter space for the leg. It results in a lookup table as shown below - each dot represents a combination of motor commands and the inplane displacement of the leg from the origin (0,0), when the motors are at their neutral location.
In the full lookup table, compiled over multiple hours and ~12 complete inplane sweeps covering the parameter space, it's visually apparent that 1. the HSA properties remain reasonably consistent over time, and 2. HSA displacement at a given set of motor values is reasonably
repeatable, regardless of the actuator's strain rate or direction of movement. The resulting dimensions of the lookup table then define the joint limits in the simulation's URDF file.
| Animated Lookup Table | Full Lookup Table |
|---|---|
 |
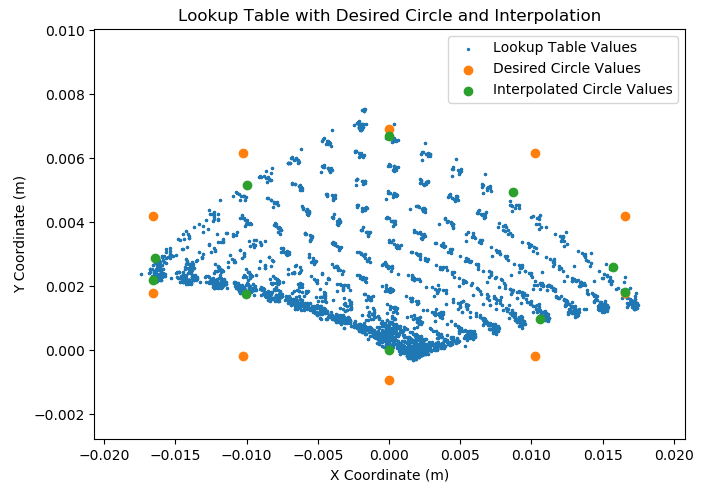 |
Finally, I perform bilinear interpolation to go from an arbitrary set of XY values in the leg's coordinate frame, to a set of motor commands that most closely replicate it. Appending this to the end of the PMTG pipeline allows translation of simulated policies into real life.
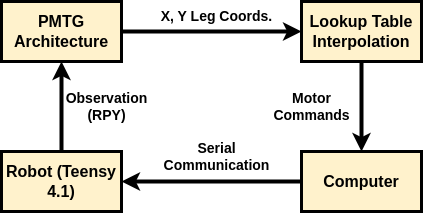
The full system diagram for running a policy on a real robot
Learning and Optimizing Gaits - in Simulation and Real Life
At long last, we're ready to perform sim-to-real transfer. Using bilinear interpolation, I demonstrated an elliptical gait - not learned, though derived from my lookup table - that exceeds the hand-tuned gait speed demonstrated in Soft Matter by ~25%.

Closed-loop circular gait in Pybullet

Closed-loop circular gait in real life
This is corroborated in the simulation results, where we can observe the robot learning significantly in only hundreds of rollouts, sometimes fewer. Initial results showed nearly 5x improvement in gait speed, largely due to the "time-warping" functionality of the policy, effectively walking far faster than the zero policy gait.
Time modulation allows quicker leg movements
However, this type of gait isn't reasonable to run on the real robot - the HSAs don't move this fast in real life. Therefore, current work focuses on slowing down gaits while still generating geometric optimization. An example is shown below in simulation, we we improve a slowed-down gait's speed (that more closely resembles how the robot walks in real-life) by a factor of three.
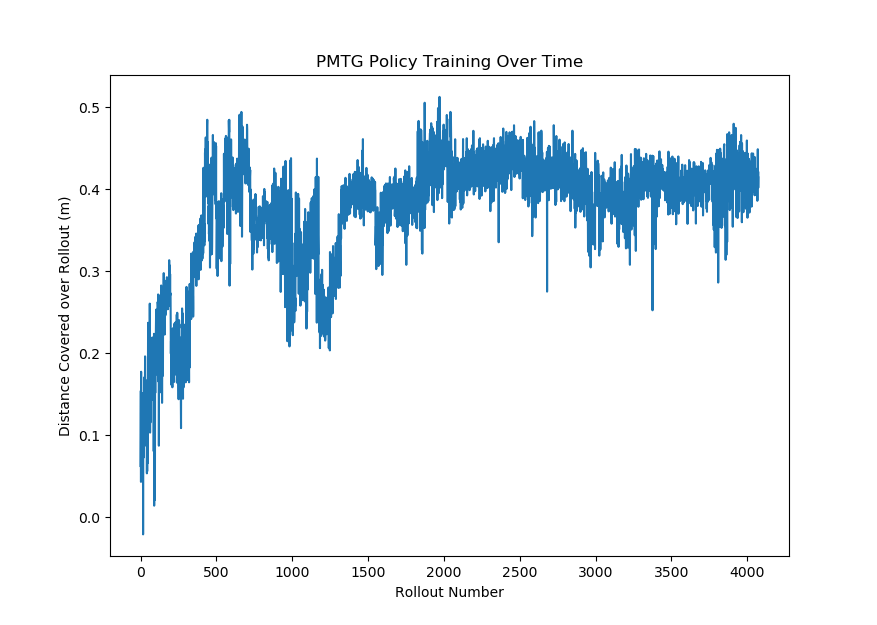
Plot of training rewards over rollout number

Optimized Pybullet gait, ~3x faster than initial policy
Final results, aiming to demonstrate a complete sim-to-real gait pipeline, are still in production with the intention of preparing a conference submission! An absolute massive thank-you to my advisors Ryan Truby and Matt Elwin, along with Pranav Kaarthik, Francesco Sanchez from the Robotic Matter Lab. From Todd Murphey's Lab, Jake Ketchum, Muchen Sun, and Thomas Berrueta were all great resources and collaborators!